WER we are and WER we think we are
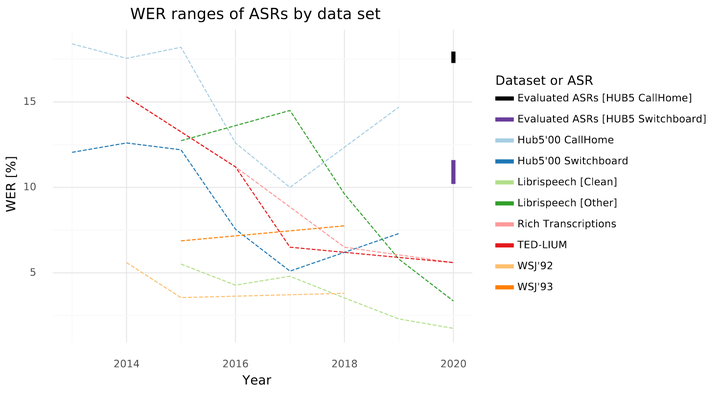 WER ranges in ASR systems. Reference values taken from the Wer are we report \cite{synnaeve_2020} and the \textit{Papers with Code} website \cite{papers_with_code} for ASR solutions published in the last 5 years. Outliers were removed for the sake of figure readability.
WER ranges in ASR systems. Reference values taken from the Wer are we report \cite{synnaeve_2020} and the \textit{Papers with Code} website \cite{papers_with_code} for ASR solutions published in the last 5 years. Outliers were removed for the sake of figure readability.Abstract
Natural language processing of conversational speech requires the availability of high-quality transcripts. In this paper, we express our skepticism towards the recent reports of very low Word Error Rates (WERs) achieved by modern Automatic Speech Recognition (ASR) systems on benchmark datasets. We outline several problems with popular benchmarks and compare three state-of-the-art commercial ASR systems on an internal dataset of real-life spontaneous human conversations and HUB'05 public benchmark. We show that WERs are significantly higher than the best reported results. We formulate a set of guidelines which may aid in the creation of real-life, multi-domain datasets with high quality annotations for training and testing of robust ASR systems.
Piotr Szymański
Assistant Professor at Wrocław University of Science & Technology; Machine Learning Engineer in Avaya Inc.; - Chairman of the Society for Beautification of the City of Wrocław; Vice-charmain of the Wrocław’s District Council of Brochów
Piotr Szymański is an assistant Professor at the Department of Computational Intelligence at the Wrocław University of Science and Technology and a Machine Learning Engineer at Avaya. Professionally involved in data analysis, statistical reasoning, geospatial data science, natural language processing, machine learning and artificial intelligence techniques. He is an alumni of the Top 500 Innovators program at Stanford University, worked in several institutions over the years incl. Hasso Plattner Institute in Potsdam, Josef Stefan Institute in Ljubljana, University of Notre Dame and University of Technology Sydney. He is the author of scikit-multilearn, a popular python library for multi-label classification. Apart from multi-label classification, Piotr published papers concerning urban data, traffic analysis and bridging the gap between ASR and NLP in spoken language understanding systems. In his free time he is an urban activist in Wrocław and a member of a city district council.